1M user đặt lệnh trên exchange-core
May 25, 2026
Nếu có 1M user đặt lệnh trên exchange-core thì phải xử lý như nào? Điểm yếu của version cơ bản và cách exchange-core-nodejs xử lý từng tầng.

Ở phần 1, chúng ta đã có một thiết kế cơ bản:
Client → API Gateway → Sequencer → Risk + Validate → Matching Engine → Order Book → WS
Mọi thứ chạy đẹp khi có vài chục user.
Nhưng khi sản phẩm bắt đầu đông, vấn đề lộ ra rất nhanh — từ 100 CCU, rồi 10K, rồi 100K, cho tới mục tiêu 1,000,000 CCU.
CCU (Concurrent Users) = số user đang active đồng thời tại một thời điểm. Không phải tổng user đăng ký, mà là số người đang giữ kết nối / đang gửi request ngay lúc đó.
Triệu chứng điển hình khi version cơ bản gặp 1M CCU:
- Server từ chối nhận request (TCP backlog đầy,
ECONNREFUSED). - Request bị treo, latency p99 nhảy từ ms lên giây.
- Event loop bị block, Node process "đứng hình".
- Tệ hơn: heap OOM, process crash, hoặc cả node sàn down.
Tại sao khi có nhiều user vào hệ thống, server của chúng ta sẽ không thể handle? Server của chúng ta sẽ gặp vấn đề ở tầng nào? Chúng ta cùng đi vào chi tiết:
🤔 Câu hỏi đặt ra
Với bản thiết kế đã vẽ ở phần 1, do chúng ta đang chọn Node.js, giả sử tất cả các phần — gateway, sequencer, risk, validate, matching engine, orderbook, websocket — đều chạy trên 1 Node.js process duy nhất.
Giả sử resource server không phải vấn đề — ta được quyền thuê cấu hình lớn nhất trên thị trường (hàng trăm vCPU, vài TB RAM, NIC 100Gbps). Liệu monolith này có chịu nổi 1M CCU không? Nếu không thì vỡ ở đâu, vì sao vỡ?
Đáp án ngắn: không, và lý do nằm ở kiến trúc, không phải ở phần cứng. Phần dưới sẽ đi qua từng tầng — từ những giới hạn dễ vá nhất (FD, kernel) tới những giới hạn không vá được bằng cách mua thêm RAM/CPU.
Khi 1M user cùng kéo tới, hệ thống sẽ vỡ tuần tự ở từng tầng. Mỗi lần vá xong một chỗ, một chỗ khác lại lộ ra, phần lớn các tầng là giới hạn của HĐH và phần cứng.
Mục lục
Phần 1 — Vì sao một kiến trúc exchange-core đơn giản sẽ không thể đáp ứng được 1M CCU
- Tầng 1 — File descriptor:
EMFILE - Tầng 2 — Kernel networking: connection bị drop im lặng
- Tầng 3 — Heap đơn khối: mọi state co-located, không thể cô lập
- Tầng 4 — Garbage Collector: pause-the-world
- Vertical scale (mua server to hơn) có cứu được không?
- Đổi sang Java hoặc Go thì sao?
- Vậy horizontal scale (nhiều instance monolith) thì sao?
- Tổng kết Phần 1: vertical lẫn horizontal scale ngây thơ đều thua
Phần 2 — Cách exchange-core-nodejs xử lý từng tầng
- API Gateway
- Ring + Producer + Consumer + SAB
- Pipeline
- Matching Engine & Order Book
- Stream data cho 1M user
- Bonus: Event sourcing & crash recovery
Phần 1 — Vì sao một kiến trúc exchange-core đơn giản sẽ không thể đáp ứng được 1M CCU
Tầng 1 — File descriptor: EMFILE: too many open files
Lỗi đầu tiên xuất hiện gần như ngay lập tức, khi mới chỉ ~1000 connection đầu tiên được chấp nhận:
Error: accept EMFILE (too many open files)
Trên Linux, mọi thứ I/O — file trên disk, TCP socket, WebSocket, pipe — đều là file descriptor (FD). Mỗi process bị giới hạn số FD mở đồng thời bởi ulimit -n, mặc định thường là 1024.
ulimit -n 1024nghĩa là: process này được phép mở tối đa 1024 file/socket cùng lúc. Connection thứ 1025 trở đi sẽ bị kernel từ chối ngay tạiaccept().
Với 1 WebSocket = 1 FD, ta chỉ chứa nổi ~1000 user. Cần nâng giới hạn:
ulimit -n 1048576
# hoặc set vĩnh viễn trong /etc/security/limits.conf
* soft nofile 1048576
* hard nofile 1048576
Tầng 2 — Kernel networking: connection bị drop im lặng
Vượt qua FD, ta gặp tầng tiếp theo: kernel network stack. Lúc này lỗi không hiện ra ở application — client chỉ thấy ECONNREFUSED, ETIMEDOUT hoặc connection thành công nhưng không bao giờ nhận được handshake reply.
Các thông số kernel mặc định trên Linux được tune cho server web bình thường, không phải cho 1M kết nối thường trú:
net.core.somaxconn = 128— kích thước queue chờaccept(). Khi application chưa kịp accept, connection mới phải xếp hàng. Hàng dài quá 128 → kernel drop SYN.net.ipv4.tcp_max_syn_backlog— half-open connection (đang TCP handshake) cũng có giới hạn.nf_conntracktable — nếu có iptables/Docker, mỗi connection chiếm 1 entry. Bảng đầy → packet bị drop không log gì cả.net.ipv4.ip_local_port_range— chỉ ảnh hưởng outbound, nhưng nếu gateway proxy đến service nội bộ, ephemeral port (~28K port) sẽ cạn rất nhanh.
Tầng 3 — Heap đơn khối: mọi state co-located, không thể cô lập
Một WebSocket "rảnh rỗi" không hề miễn phí. Chi phí RAM cho 1 connection gồm:
- Kernel socket buffer (
rmem+wmem) — ~85KB + 85KB = ~170KB - Object + per-connection state (Node
ws) — ~30–60KB heap - TLS context (nếu dùng WSS) — thêm ~20–40KB
- Buffer cho subscription, user state, throttler... — ~10–30KB
Tổng cộng: ~250KB cho mỗi WS idle → 1M user × 250KB ≈ 250GB RAM.
RAM thì mua được — AWS x1e.32xlarge có 3.9TB, u-6tb1.56xlarge có 6TB. 250GB không phải vấn đề.
Vấn đề thật sự nằm ở kiến trúc: trong monolith 1 process, toàn bộ state nằm trong 1 V8 heap duy nhất.
- 1M WebSocket session + buffer
- Order book của mọi symbol
- Balance + position của toàn bộ user
- Journal buffer chờ flush
- Sequencer state, rate limiter, market data fanout queue
- Mọi closure, callback, promise đang in-flight
Cùng một heap, cùng một GC arena, cùng một bộ luật allocation. Hệ quả không phải "thiếu RAM" mà là mọi component giẫm chân nhau qua RAM:
- Không có isolation: một bug trong WS handler allocate vô hạn sẽ kiến heap chạm "--max-old-space-size" -> process chết. Crash 1 thành phần (gateway) = mất toàn bộ 1M user cùng lúc.
- Cache locality vỡ: order book cần nóng trong L1/L2 (~32–256KB), nhưng 1M WS handler liên tục allocate đẩy mọi thứ khỏi cache. Mỗi
matchOrder()phải chờ cache miss → latency tăng 10–100 lần dù CPU vẫn rảnh. - Không có backpressure boundary: WS push chậm → buffer phình trong cùng heap → matching engine chịu GC pause theo. Một component yếu kéo cả hệ xuống.
→ Cho server 6TB RAM không giải quyết được. Phải tách state ra nhiều process / nhiều heap riêng biệt, mỗi cái có boundary rõ ràng.
Tầng 4 — Garbage Collector: pause-the-world
Heap phình to vì 1M connection cũng phá hỏng GC. V8 dùng generational GC để dọn heap, nhưng khi heap > vài GB, mỗi lần major GC stop-the-world có thể kéo dài hàng trăm ms tới vài giây.
Trong khoảng thời gian đó:
- Matching engine bị dừng hoạt động.
- WebSocket không nhận được heartbeat → client tự disconnect.
- Khi GC xong, 1M client cùng reconnect → thundering herd → quay lại Tầng 1.
Vertical scale (mua server to hơn) có cứu được không?
Phản xạ đầu tiên khi monolith vỡ: "Thuê server khủng hơn — vài trăm core, vài TB RAM — chắc xong?". Không.
Lý do: với CPU, có hai thứ khác nhau:
- Số core: mua thêm rất dễ, server hiện đại có 192 core là chuyện thường.
- Tốc độ 1 core riêng lẻ: từ ~2010 đã đụng trần vật lý. Đẩy nhanh hơn nữa thì CPU quá nóng, silicon không chịu nổi. Vì vậy 10 năm qua, 1 core gần như không nhanh hơn — các hãng chip chỉ thêm nhiều core chứ không làm 1 core nhanh hơn.
Mà Node.js có một đặc tính cốt tử: JS chỉ chạy trên 1 core. Ghép lại:
- Monolith Node.js bị giới hạn cứng bởi tốc độ của 1 core.
- 191 core còn lại của server khủng — không chạy được JS, chỉ để đó.
- Mua server tương lai cũng vô ích, vì 1 core cũng không nhanh hơn được mấy.
→ Đây là giới hạn vật lý, không phải vấn đề tiền. Cách duy nhất tận dụng được nhiều core là tách thành nhiều process / worker_threads rồi cho chúng nói chuyện với nhau — chính là kiến trúc của exchange-core-nodejs ở Phần 2.
Vậy horizontal scale (nhiều instance monolith) thì sao?
Phản xạ tiếp theo: "Vertical scale không được, vậy mình deploy N instance monolith và load balance qua Kafka/Redis — như mọi web service khác. Hợp lý chứ?"
Đối với web service thông thường (stateless REST API), đúng. Đối với exchange-core, sai. Lý do: exchange-core là stateful + ordering-critical + consistency-critical — 3 tính chất mà horizontal scale ngây thơ phá vỡ ngay.
Giả sử ta deploy 10 instance exchange-core, đặt Kafka đứng trước phân phối order:
┌─→ instance-1 (orderbook + balance)
Client → Kafka topic ─┼─→ instance-2 (orderbook + balance)
│ ...
└─→ instance-10
Các vấn đề lập tức xuất hiện:
1. Race condition trên orderbook chung
Nếu 2 instance cùng nhận order cho symbol BTC/USDT, cả 2 đều muốn match và update orderbook. Orderbook ở đâu?
- Nếu mỗi instance giữ orderbook riêng → state divergence. Cùng 1 order resting có thể bị match trên instance-1 (filled) và còn nguyên trên instance-2 (unfilled) — trade ma.
- Nếu orderbook lưu ở DB / Redis chung → mỗi op = round-trip mạng (~100µs–1ms). 1M ops/s vượt sức 1 Redis. Sharded Redis thì lại đụng vấn đề atomicity (multi-key transaction).
- Nếu dùng distributed lock (Redlock, ZooKeeper) → mỗi PLACE = 1 lock acquire ~1–5ms. Trở thành 1ms p99 → 5ms p99, mất hết lợi thế tốc độ.
→ Chỉ có 1 cách đúng: route mọi order của 1 symbol về đúng 1 instance (sticky by symbol). Nhưng lúc đó instance đó lại trở thành monolith con — kế thừa lại mọi vấn đề Tầng 3, 4, 5.
2. Ordering toàn cục bị phá
Sàn cần price-time priority: order đến trước được match trước. Khi 2 client gửi cùng lúc qua 2 instance khác nhau:
- Kafka producer A → broker-1 → instance-1 (T=100ns)
- Kafka producer B → broker-2 → instance-2 (T=120ns)
Nhưng broker-1 và broker-2 không có đồng hồ chung. NTP drift giữa các broker thường 1–5ms. Order A có thể được sắp xếp sau order B mặc dù tới trước.
Để khôi phục ordering toàn cục, cần:
- Single Kafka partition cho mỗi symbol → quay lại single-writer (mất luôn lợi ích scale).
- Hoặc distributed consensus (Raft, Paxos) → 5–10ms latency mỗi op (vài lần round-trip).
- Hoặc Spanner/TrueTime → cần atomic clock dedicated, $$$.
3. Cross-instance balance — đúng nghĩa "race condition"
User Alice đặt 2 order cùng lúc trên 2 connection khác nhau, cả 2 đều ngốn balance:
T=0ms: Alice balance = $1000
T=1ms: Order A đến instance-1, check balance → $1000 OK, lock $800
T=2ms: Order B đến instance-2, check balance → $1000 OK (chưa thấy A!), lock $500
T=3ms: Cả 2 instance đều settle → tổng lock $1300, vượt $1000 → âm balance.
Đây là classic double-spend. Vá bằng:
- Pessimistic lock per user ở Redis/DB → mỗi order = round-trip + contention. Hot user (HFT bot) đứng hình.
- Optimistic concurrency (CAS) → 1 order bị reject phải retry → tăng latency, mất fairness.
- Saga / 2-phase commit → 2 round-trip + rollback logic phức tạp.
Mọi giải pháp đều đánh đổi latency để có consistency — không hợp với exchange (đòi cả 2).
4. Kafka/Redis tự nó là bottleneck
- Kafka: producer → broker → fsync → consumer ack. Best-case latency 5–10ms. Exchange cần p99 dưới 1ms. Sai 1 bậc.
- Redis: single-thread, ~100K–500K ops/s/instance. 1M ops/s cần shard Redis → mất atomicity cross-shard.
- Cả 2 cũng cần HA cluster riêng, tự nó là 1 distributed system phải vận hành, monitor, failover.
5. Market data fanout phân mảnh
User Alice connect WS tới instance-3 nhưng trade xảy ra trên instance-7 → instance-7 phải biết Alice ở đâu để push update. Cần:
- Cross-instance pub/sub (Redis stream / Kafka) → thêm 1–5ms latency.
- Session registry (ai connect ở đâu) → consistency, failover, lookup cost.
1M user × 10 msg/s = 10M msg/s qua pub/sub layer — không hệ pub/sub nào trên thị trường handle nổi mà giữ p99 < ms.
6. Failure mode phức tạp hơn nhiều
Monolith chết → mất hết, nhưng đơn giản (restart). Horizontal:
- Network partition: instance-1 và instance-2 mất liên lạc → cả 2 tưởng mình là leader → split-brain → orderbook diverge → không cứu được.
- Slow node: 1 instance GC pause 500ms → order routing vẫn đi tới nó → backpressure dồn ngược lên Kafka → cascade failure.
- Replication lag: leader die → follower lên thay nhưng trễ 50ms → mất 50ms của trade gần nhất.
Kết luận horizontal scale
Horizontal scale monolith kiểu Web 2.0 (stateless instance + load balancer + DB chung) không áp dụng được cho exchange-core vì các tính chất sau:
- State chung — web service: DB cache OK, eventual consistency chấp nhận được. Exchange-core: phải strong consistency real-time.
- Ordering — web service: không quan trọng. Exchange-core: price-time priority, ordering toàn cục.
- Latency — web service: 50–200ms OK. Exchange-core: p99 < 1ms.
- Race condition — web service: DB lock chấp nhận được. Exchange-core: mỗi lock = mất fairness, mất throughput.
→ Vertical scale chết vì giới hạn của phần cứng và OS, horizontal scale ngây thơ chết vì stateful + ordering. Cách duy nhất là kiến trúc lai: stateless layer (gateway, fanout) scale ngang, stateful layer (matching, orderbook) shard theo symbol + single-writer per shard, kết nối qua in-process channel thay vì network. Đây chính là hướng exchange-core-nodejs đi.
Tổng kết Phần 1: vertical lẫn horizontal scale ngây thơ đều thua
Tổng hợp 4 hướng tiếp cận đã thử và lý do thất bại:
Vertical scale (server to hơn)
- Hệ quả: 1 core CPU không đủ, heap monolith khiến GC quá tải.
- Vì sao thua: single-thread performance đụng trần silicon từ ~2010; 1 heap = 1 GC arena.
Đổi language (Java / Go)
- Hệ quả: có nhiều thread cho I/O nhưng vẫn 1 process, 1 matching engine.
- Vì sao thua: matching single-writer + heap đơn khối vẫn là ràng buộc kiến trúc, không runtime nào tránh được.
Horizontal scale ngây thơ (N instance + Kafka/Redis)
- Hệ quả: race condition trên orderbook, mất ordering toàn cục, double-spend balance, fanout phân mảnh.
- Vì sao thua: exchange-core stateful + ordering-critical + consistency-critical — phá vỡ mọi giả định của load balancing stateless.
Muốn đi tới 1M CCU, bắt buộc:
- Tách connection layer (stateless) ra khỏi business logic (stateful) — gateway scale ngang theo CPU/RAM, matching engine giữ single-writer.
- Shard state theo symbol — mỗi shard là 1 single-writer instance, không cross-shard contention.
- Cô lập failure boundary — gateway crash không kéo matching engine đi theo, ngược lại.
- In-process channel cho hot path — không Kafka/Redis trên đường lệnh, dùng SharedArrayBuffer + ring buffer (sẽ thấy ở Phần 2).
- Mechanical sympathy — pre-allocate, reuse buffer, tránh GC pressure trên đường lệnh.
→ Đây chính là hướng exchange-core-nodejs đi.
Tiếp theo sẽ mổ xẻ từng phần trong exchange-core nodejs xử lý 1M CCU như nào.
Phần 2 — Cách exchange-core-nodejs xử lý từng tầng
Như đã nói bên trên, chúng ta sẽ cải tiến architecture theo hướng sharding bằng symbol. Nghĩa là ta horizontal scale, nhưng tất cả các order của 1 symbol chỉ được xử lý trên 1 process duy nhất.
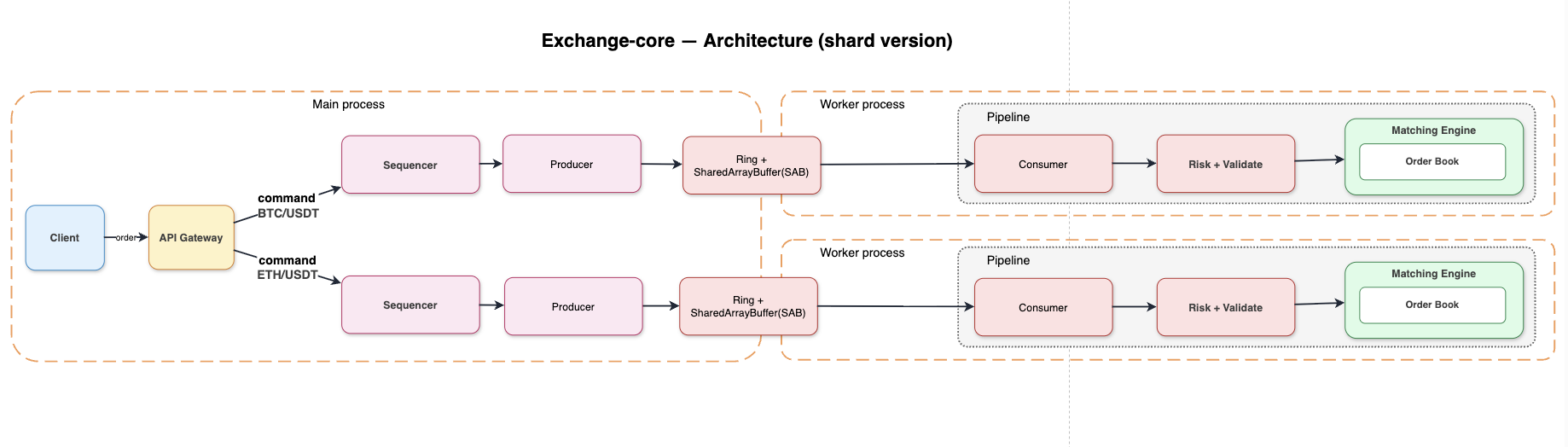
1. API Gateway
API Gateway là nơi đầu tiên tiếp nhận các request của client, nó không nên dành quá nhiều thời gian để handle 1 request. API Gateway sẽ chỉ làm tác vụ sau:
- Verify HMAC + JWT với tốc độ nhanh, không gọi DB ở hot path.
- Rate limit per uid (không phải per IP) — chặn bot xấu mà không chặn user thật phía sau cùng NAT.
- Enqueue user's request cho các bộ phần phía sau xử lý.
Vì gateway là stateless, vì vậy có thể chọn scale horizontal mà không ảnh hưởng tới tính đúng sai của dữ liệu.
2. Ring + Producer + Consumer + SAB
Việc dùng 1 process NodeJS là không khả thi, ta cần scale nhiều process (Node worker_threads hoặc process riêng). Nhưng các process này cần giao tiếp với nhau — vì command từ gateway phải tới matching, kết quả từ matching phải về gateway. Cần một kênh liên kết giữa các process — chọn cái nào?
Có 3 ứng cử viên chính:
Redis (list / stream)
- Ưu: dễ dùng, persistent, có sẵn HA.
- Nhược: mỗi op = 1 round-trip TCP (~100µs–1ms). Serialize JSON tốn CPU + GC. Redis là single point. 1M ops/s vượt sức 1 instance.
Kafka
- Ưu: throughput cao (~triệu msg/s/cluster), data persistent.
- Nhược: latency vài ms ngay cả khi tốt nhất. JVM + cluster cost lớn. Vẫn phải qua network stack OS.
SharedArrayBuffer (SAB)
- Cách hoạt động: vùng nhớ chung giữa các thread trong cùng process, đọc/ghi qua
Atomics. - Ưu: latency nanosecond. Không network, không serialize. Lock-free. Zero copy.
- Nhược: chỉ dùng được giữa các thread trong cùng process (không cross-host). Phải tự encode binary. Persistent phải tự lo (journal).
Với exchange-core ở quy mô 1 node, Redis / Kafka thêm 100µs–10ms mỗi hop là không chấp nhận được khi mục tiêu p99 dưới ms.
→ Chọn SharedArrayBuffer (SAB) + worker_threads của Node.
Producer, consumer, ring là gì?
Có SAB rồi, vẫn cần một giao thức để 2 thread biết "producer ghi tới vị trí ô nhớ nào rồi, consumer đọc tới ô nhớ nào rồi". Đó là ring buffer:
- Ring buffer = mảng cố định size, có 2 con trỏ
producerSeqvàconsumerSeqchạy vòng (wrap around). - Producer = thread ghi vào ring (ở đây là main thread đứng sau gateway).
- Consumer = thread đọc ra (ở đây là matching worker).
SharedArrayBuffer layout:
┌─────────┬─────────┬─────────┬─────────┬──────────────────────────┐
│producer │consumer │capacity │slotSize │ slots[0..capacity-1] │
│ Seq │ Seq │ │ │ (binary command rec.) │
│ (8B) │ (8B) │ (8B) │ (8B) │ │
└─────────┴─────────┴─────────┴─────────┴──────────────────────────┘
↑ ↑ ↑
ghi bởi ghi bởi cả 2 đều đọc/ghi vào đây
producer consumer (mỗi slot do 1 bên chạm
tại 1 thời điểm)
Ring buffer là gì?
Ring buffer là cấu trúc dữ liệu rất phổ biến trong các exchange-core trên thế giới, thường đi kèm với Disruptor pattern — kiến trúc do LMAX (sàn FX của Anh) công bố năm 2011. Disruptor chứng minh rằng chỉ với ring buffer + lock-free + mechanical sympathy (tận dụng đặc tính CPU cache, bitwise, single-writer), 1 core có thể đạt 6 triệu ops/giây — vượt xa mọi queue truyền thống (ArrayBlockingQueue, LinkedBlockingQueue) tới 1–2 bậc. Sau LMAX, ý tưởng này được port sang rất nhiều exchange/HFT firm (Crypto.com, Coinbase nội bộ, các sàn phái sinh truyền thống) và cả các hệ low-latency ngoài tài chính (game server, ad-tech).
Bản chất ring buffer không phải là một mảng vô hạn. Nó là mảng cố định size (ví dụ 8 slot), nhưng 2 con trỏ producerSeq và consumerSeq thì chạy mãi mãi tăng dần (0, 1, 2, ... triệu, tỷ, ...). Khi sequence vượt qua cuối mảng, nó quay vòng về đầu — đó là lý do gọi "ring":
producerSeq=10 (đang ghi slot[2])
↓
┌──────[2]──────┐
[1] [3]
[0] [4]
\ /
[7]─────[6]─[5]
↑
consumerSeq=6 (đang đọc slot[6])
Ưu điểm của Ring buffer
- Không allocate: slot là binary record cố định 256 bytes, ghi đè lên bộ nhớ cũ → zero garbage, giảm tải việc cho GC.
- Layout tuyến tính trong RAM: cache-friendly, CPU prefetcher đoán đúng → L1 hit gần 100%.
- Bitwise wrap: tính vị trí slot chỉ tốn 1 cycle CPU, không cần phép chia thật.
- Lock-free: producer chỉ ghi slot phía trước, consumer chỉ đọc slot phía sau → 2 bên không bao giờ chạm cùng 1 slot tại cùng thời điểm → không cần mutex.
- Deterministic: sequence tăng đơn điệu, mỗi command có 1 ID duy nhất → thuận lợi cho journal, replay, debug.
Trong các ưu điểm trên, bitwise wrap chính là điểm "ảo diệu" làm ring buffer nhanh đến vậy. Về mặt toán học, ta cần slotIndex = sequence % capacity (chia lấy dư). Nhưng nếu capacity là lũy thừa của 2, có thể thay bằng:
slotIndex = sequence & (capacity - 1)
Wrap qua bitmask:
& (capacity - 1)chỉ tốn 1 cycle CPU, nhanh hơn% capacity(phép chia thường mất 20–40 cycle).
Nó hoạt động ra sao — ví dụ từng bước
Trước tiên, quy tắc bất biến mà ring luôn đảm bảo để 2 thread không giẫm chân nhau:
consumerSeq ≤ producerSeq ≤ consumerSeq + capacity
producerSeq == consumerSeq→ ring rỗng (consumer phải ngủ chờ data).producerSeq - consumerSeq == capacity→ ring đầy (producer phải chờ consumer đọc xong).- Khoảng cách giữa 2 con trỏ = số slot đang chứa data chưa đọc.
Minh hoạ bitwise wrap với capacity = 8:
sequence sequence & 7 → slot thực tế
─────────────────────────────────────────────
0 0 slot[0]
1 1 slot[1]
... ... ...
7 7 slot[7]
8 0 slot[0] ← quay lại đầu
9 1 slot[1]
1000 0 slot[0]
Sequence cứ tăng tuyến tính, nhưng vị trí ghi thực quay vòng. Bây giờ ta đi qua một kịch bản hoàn chỉnh với capacity = 4, ring khởi đầu rỗng (producerSeq = 0, consumerSeq = 0):
Bước 1: Producer ghi command "A"
slot[0 & 3] = slot[0] ← "A"
producerSeq = 1
ring: [A][ ][ ][ ]
P=1, C=0 (1 item)
Bước 2: Producer ghi "B", "C"
ring: [A][B][C][ ]
P=3, C=0 (3 items)
Bước 3: Consumer đọc "A"
slot[0 & 3] = slot[0] → "A"
consumerSeq = 1
ring: [_][B][C][ ] (slot[0] đã "giải phóng", có thể ghi đè)
P=3, C=1
Bước 4: Producer ghi "D", "E"
slot[3 & 3] = slot[3] ← "D" (producerSeq=4 sau khi ghi D)
slot[4 & 3] = slot[0] ← "E" ← QUAY VÒNG! producerSeq=5
ring: [E][B][C][D]
P=5, C=1 (4 items — FULL)
Bước 5: Producer muốn ghi "F" nhưng ring đầy
producerSeq - consumerSeq == capacity → spin wait
Đợi consumer đọc xong ít nhất 1 slot mới ghi được.
Bước 6: Consumer đọc "B", "C", "D"
consumerSeq = 4
ring: [E][_][_][_]
P=5, C=4 (1 item)
Bước 7: Producer ghi "F"
slot[5 & 3] = slot[1] ← "F"
producerSeq = 6
ring: [E][F][_][_]
P=6, C=4
Nhìn vào dòng P=5, C=1 ở bước 4: sequence là 5 và 1, nhưng vị trí slot vật lý đã quay về slot[0] và slot[1]. Sequence không bao giờ reset — đây là điểm quan trọng để debug, journal, replay: mỗi command có một sequence number duy nhất tăng dần trong suốt vòng đời hệ thống, dù slot vật lý bị ghi đè nhiều lần.
Ring buffer có đáp ứng được bài toán 1M CCU không?
Câu hỏi tự nhiên: ring có size cố định (ví dụ 8192 slot), vậy với 1M user đặt lệnh đồng thời thì có đủ chỗ không? Ring có bị tràn không?
Câu trả lời: có đáp ứng được — vì ring không cần chứa 1M command cùng lúc, nó chỉ cần đủ chỗ cho lượng command in-flight giữa producer và consumer tại 1 thời điểm. Với consumer xử lý ở tốc độ nanosecond/op (lock-free + cache-friendly), một ring 8192 slot có thể nuốt burst từ 1M user mà vẫn còn dư rất nhiều.
Trường hợp xấu — consumer bị treo lâu (GC pause, slow disk khi journal, hot symbol nghẽn...) → ring đầy → producer kích hoạt backpressure:
- Spin wait vài µs (chờ consumer giải phóng slot).
- Overflow buffer trong main thread + log warning.
- Trả 503 về client để tự bảo vệ — không bao giờ "mất command âm thầm".
Chi tiết về cách producer/consumer phối hợp, đánh thức nhau qua Atomics.wait/notify, và xử lý ring đầy sẽ nói ngay ở phần dưới.
3. Pipeline
Sau khi consumer (matching worker) lấy được command ra khỏi ring, bên trong worker là một pipeline tuần tự:
[command từ ring]
│
▼
┌───────┐
│ R1 │ Risk preCheck: đủ tiền? hold funds.
└───┬───┘
│ pass
▼
┌───────┐
│ ME │ Matching Engine: tìm match trong order book, emit fills.
└───┬───┘
│
▼
┌───────┐
│ R2 │ Risk postSettle: chuyển tiền, thu fee, release hold dư.
└───┬───┘
│
▼
┌────────────┐
│ Journal │ ghi event xuống disk (CRC32, append-only).
└─────┬──────┘
│
▼
┌────────────┐
│ MDP │ publish event vào market data bus (mục 6).
└─────┬──────┘
│
▼
┌────────────┐
│ result ring│ gửi result về main thread → resolve Promise client.
└────────────┘
Đặc điểm quan trọng:
- Mỗi stage chạy đồng bộ tuần tự trong 1 thread — không
awaitgiữa các stage. Sự song song là giữa các shard, không phải bên trong 1 shard. - R1 trước, R2 sau matching → bảo toàn invariant "không chi tiêu vượt mức" và "balance toàn hệ thống bảo toàn" cùng lúc.
- Journal trước khi gửi result → nếu sập sau khi journal nhưng trước khi reply, replay sẽ áp dụng lại — không mất.
- MDP publish vào in-process bus → không block pipeline, không I/O ở stage này.
4. Matching Engine & Order Book
Đến đây, kiến trúc đã có: command đi qua ring → vào 1 matching worker (1 shard = 1 symbol = 1 thread). Bài toán còn lại nằm bên trong 1 shard: matching engine làm gì với command, và order book được tổ chức như thế nào để xử lý hàng trăm nghìn ops/giây trên 1 core?
Matching Engine làm gì?
Matching engine là phần mutate order book và sinh ra trade. Sàn nào cũng tuân theo price-time priority:
- Order có giá tốt hơn được match trước (bid giá cao nhất, ask giá thấp nhất).
- Cùng giá thì FIFO theo thời gian đến (sequence trong ring chính là timestamp duy nhất).
Một vòng đời command qua matching engine:
[command từ ring]
│
▼
┌─────────────────────────┐
│ Parse: PLACE/CANCEL/ │
│ MOVE/MARKET │
└────────────┬─────────────┘
│
┌──────────┼──────────┐
▼ ▼ ▼
PLACE CANCEL MARKET
│ │ │
│ │ │
▼ ▼ ▼
Tìm best Lookup Walk best
opposite orderId → → worst,
price, unlink O(1) fill đến
fill đến khi đủ qty
hết qty hoặc hết sổ
│
▼
Còn dư? → insert vào sổ phía mình
│
▼
Emit fills + book delta
Mỗi thao tác phải đạt:
- PLACE limit: O(log n) chấp nhận được, O(1) tốt nhất.
- CANCEL: O(1) (1M user spam cancel/replace là chuyện thường).
- Find best bid/ask: O(1) hoặc O(log n) — mỗi MATCH gọi 1 lần.
- Walk price levels: O(k) với k = số level chạm (market order quét nhiều level).
Vì matching đã single-thread trong 1 shard nên không có lock, không có async. Toàn bộ vòng đời command chạy tuần tự trong cùng 1 stack frame của worker → CPU không bao giờ phải context-switch hoặc đợi I/O ở hot path.
Order Book được thiết kế như thế nào?
Order book là cấu trúc dữ liệu bị đụng nhiều nhất trong cả hệ thống. Có vài lựa chọn cổ điển:
Map<price, Bucket> + sorted keys
- Insert/search O(log n), best bid/ask O(log n).
- Cache-unfriendly, GC pressure khi alloc Order object.
- Đủ cho ~10K orders trong sổ, không đủ cho 1M.
Skip-list
- Insert/search O(log n), best bid/ask O(1).
- Pointer chasing qua node random trong RAM → phá L1 cache.
- Lock-free version có sẵn (Java
ConcurrentSkipListMap).
B+ tree
- Insert/search O(log n), best bid/ask O(log n).
- Block-oriented → cache-friendly hơn skip-list.
- Khó implement lock-free đúng cách.
Adaptive Radix Tree (ART) — exchange-core-nodejs chọn
- Insert/search O(k) với
k= số byte của key (≤ 8 cho price 8-byte). Không phụ thuộc số phần tử. - Best bid/ask O(1) qua
first/last. - Adaptive node 4 / 16 / 48 / 256 children → vừa tiết kiệm RAM, vừa cache-friendly.
Tại sao là ART?
- Độ phức tạp O(k) với
k= số byte của key (price là 8-byte integer → k ≤ 8) → không phụ thuộc số order trong sổ. Có 100 hay 10 triệu order, lookup vẫn cùng tốc độ. - Adaptive node: tự động chọn loại node 4 / 16 / 48 / 256 children theo mật độ → tiết kiệm RAM gấp nhiều lần trie thường, đồng thời giữ data tuyến tính trong RAM → cache-friendly.
- Hỗ trợ
floor/ceiling/first/lastcực nhanh — chính xác là cái matching cần (tìm best price, walk các level lân cận). - Hợp với price làm key: price sau khi scale là integer; các bit cao của các price gần nhau thường giống nhau → ART nén được prefix chung → 1 node giữ nhiều price → cache hit cao.
Kèm theo ART, exchange-core-nodejs còn áp dụng 3 trick mechanical sympathy:
- Object pool cho
Order,Bucket, ART node — pre-allocate sẵn 1 lượng lớn, recycle lại khi cancel/fill. Hot path không cónewnào → zero GC pressure → không có pause stop-the-world giữa các trade. - Intrusive doubly-linked list: pointer
prev/nextđược nhúng thẳng vào structOrder, không có wrapper node. Cancel = O(1) vì chínhOrderbiết vị trí của mình trong queue, chỉ cầnprev.next = next; next.prev = prev. HashMap<orderId, Order>: lookup trực tiếpOrdertheoorderIdmà không cần walk sổ. Cancel chỉ tốn 1 hash lookup + 2 pointer assign.
Kết quả: 3 thao tác nóng nhất đều deterministic và rất rẻ:
- PLACE = ART insert + linked-list append → O(k) + O(1).
- CANCEL = HashMap lookup + intrusive unlink → O(1).
- MATCH = ART first/last + walk linked list → O(1) tới best price, sau đó O(k_fill) cho phần fill.
Bảo đảm đúng: dual-implementation
Cấu trúc nhanh kiểu này dễ bug ngầm (off-by-one, pointer dangling, ART node split sai...). exchange-core-nodejs giữ 2 implementation chạy song song trong test:
OrderBookNaive—Map<price, Bucket>+ sorted keys, chậm nhưng dễ kiểm chứng bằng mắt → làm reference.OrderBookDirect— ART + object pool + intrusive list → production.
Sau mỗi command, gọi stateHash() cho cả 2 impl rồi so sánh. 10K commands × 10 seed random → 100% match → bảo đảm impl nhanh không lệch với reference. Đây là cách rẻ nhất để vừa giữ tốc độ vừa khỏi lo correctness regression.
Có đáp ứng được 1M CCU không, vì sao?
Đầu tiên cần dịch "1M CCU" ra load thực tế trên matching engine. CCU không bằng ops/s:
- 1M user online, nhưng đa số xem giá / hold position, không spam order.
- Theo benchmark các sàn lớn (Binance, Coinbase): trung bình ~5–20 orders/user/phút vào giờ cao điểm, peak burst ~100 orders/user/phút trong sự kiện lớn (FOMC, halving).
- 1M CCU × 10 ops/phút ≈ ~170K ops/s steady, peak ~1M ops/s trong burst vài giây.
Tải này được chia cho N shard (theo symbol). Giả sử 16 shard, BTC chiếm 70% volume → shard BTC nhận ~120K ops/s steady, peak ~700K ops/s. Các shard còn lại rất nhẹ.
Câu hỏi đổi thành: 1 matching worker có gánh nổi ~700K ops/s không?
Cộng từng yếu tố tốc độ đã thiết kế ở trên:
- Single-thread, không lock → không có contention, không có pause.
- ART O(k) với k ≤ 8 → ~50–200ns/op cho lookup/insert.
- Object pool → 0 allocation trên hot path → 0 GC pause.
- Intrusive linked list → cancel ~30ns.
- Cache-friendly layout → L1 hit ~95%, CPU không stall vì memory.
- Binary command qua ring → decode ~20ns, không JSON parse.
Cộng lại: ~500ns – 2µs/order cho hot path đầy đủ (R1 → ME → R2). Tức 500K – 2M ops/s/core. Vừa khít với hot shard BTC, dư sức với các shard khác.
Đây là con số đã được chứng minh bởi LMAX Disruptor (6M ops/s/core năm 2011 trên Java) và các bench của exchange-core-java (chronicle, ART) đạt tương tự. exchange-core-nodejs port nguyên triết lý đó → đạt được throughput tương đương trên Node.js, ngay cả khi V8 chậm hơn JVM ở vài chỗ — vì hot path không chạm vào V8 features đắt tiền (không closure capture, không JSON, không Promise).
Các edge case còn lại đã được xử lý ở các tầng khác trong kiến trúc, không thuộc về matching engine:
- Hot user (HFT bot flood 1 shard) → rate limit per uid ở gateway (mục 1).
- Hot symbol (BTC quá tải 1 core) → vẫn vừa 1 core với thiết kế trên; nếu vượt thì sub-shard theo price range.
- Cross-shard order (user trade 2 symbol) → user homed cùng shard với symbol (đơn giản hoá), production cần saga 2-phase.
- Cross-shard ordering → chấp nhận chỉ có per-shard ordering, không có global timestamp toàn cục (đổi consistency lấy throughput).
5. Stream data cho 1M user
Vấn đề
Mỗi trade khớp sinh ra rất nhiều event cần đẩy ra:
- L2 order book update (top-N price level snapshot hoặc delta).
- Trade stream (giá, volume, side).
- Candlestick update (1m, 5m, 1h...).
- User stream cho 2 user liên quan tới trade (fill notification, balance change).
Với 1M user subscribe, một trade duy nhất có thể trigger hàng trăm nghìn message cần đẩy đi. Nếu matching engine tự push ra socket:
- Matching engine biến thành I/O-bound → throughput sụp.
- Một slow client (mạng kém) làm chậm cả matching.
- WS write nằm trong event loop → block.
Cách exchange-core-nodejs làm
Tách hẳn Market Data Publisher (MDP) khỏi critical path:
[Matching Engine]
│ emit event (in-memory)
▼
[ Market Data Bus (in-process pub/sub) ]
│
┌───┼─────────────┬──────────────┐
▼ ▼ ▼ ▼
L2 Trade Candle User stream
pub pub aggregator publisher
│ │ │ │
└───┴─────────────┴──────────────┘
│
▼
[ WS Gateway workers ]
│
▼
[ 1M WS clients ]
Chiến thuật fan-out:
- Matching emit event vào in-process bus — không I/O, latency ~nanosecond.
- L2 throttle: snapshot 10ms/lần thay vì mỗi tick → giảm bandwidth × 100. User không thấy được sự khác biệt < 10ms.
- Delta encoding: chỉ gửi price level thay đổi, không gửi cả sổ. Một burst trade 1000 lệnh có thể gộp thành 1 delta.
- WS gateway worker scale ngang: mỗi worker giữ ~50K connection, có thể tới 20–30 worker process trên 1 node.
- Per-client backpressure: nếu 1 WS client chậm (mạng kém), publisher drop snapshot cũ của client đó (L2 chỉ cần snapshot mới nhất, không cần history). User nhanh không bị ảnh hưởng.
- Binary frame (cbor / protobuf / custom) thay vì JSON → giảm size 3-5×, parse nhanh hơn.
- Group fan-out: nhiều client subscribe cùng channel → encode một lần, gửi N lần. Không encode lại cho mỗi client.
Kết quả
Matching engine có thể đẩy hàng trăm nghìn event/s ra bus mà không bị I/O kéo xuống. WS workers tự lo việc fan-out — scale ngang theo số connection.
6. Bonus: Event sourcing & crash recovery
1M user nghĩa là khi sàn sập, không được mất 1 lệnh nào và không được khớp lại sai.
- Mọi command sau sequencer được journal xuống disk (length-prefix + CRC32) trước khi apply.
- Định kỳ tạo snapshot toàn bộ state.
- Recovery: load snapshot gần nhất → replay journal entries sau snapshot point → state khôi phục bit-exact.
- Test thực tế:
kill -9giữa stream → restart →stateHashgiống hệt trước khi kill.
Đây cũng là lý do toàn bộ pipeline phải deterministic — sequencer là nguồn timestamp duy nhất, không Date.now() rải rác, không Math.random trong hot path, không async giữa các stage.
Tổng kết
So sánh từng tầng giữa v1 (vài chục user) và v2 (1M CCU):
Gateway
- v1: Express, sync auth, monolith.
- v2: Fastify, REST/WS tách plane, rate limit per uid, scale ngang.
Sequencer
- v1: DB autoincrement.
- v2:
Atomics.addtrên SAB, single writer, ns-level.
Channel giữa các stage
- v1: function call / Redis / Kafka.
- v2: SharedArrayBuffer + ring buffer + Atomics (lock-free SPSC).
Pipeline
- v1: mọi thứ trong 1 hàm async.
- v2: R1 → ME → R2 → Journal → MDP → result (tuần tự, không await).
Matching engine
- v1: 1 instance + lock.
- v2: shard theo symbol, single-thread per shard, không lock.
Order book
- v1:
Map<price, [order]>. - v2: ART + object pool + intrusive linked list.
Market data stream
- v1: push thẳng từ matching.
- v2: MDP tách riêng, in-process bus, throttle + delta + binary + per-client backpressure.
Recovery
- v1: snapshot DB.
- v2: journal CRC32 + snapshot + replay, bit-exact.